The second yjs update saves successfully to the database.
The first update fails to save to the database (e.g. database issue + user switches off the computer before the retry can happen)
When loading the document from the database, the history is broken because the second update is based on the missing first update. If the user were to create further updates, they wouldn’t apply because yjs waits for the missing first updates (which will never arrive).
We encountered this issue sometimes because we use Prosemirror/yjs with two providers:
y-webrtc for low latency communication between browsers
custom provider that stores updates in DynamoDB for persistency (we can’t use the y-websocket provider as our application is serverless). Notable, this provider doesn’t distribute the updates but only stores them in DynamoDB.
This setup has led to corrupt documents because some updates were distributed via webrtc but failed to be stored in DynamoDB. This meant, other users were building updates based on updates that didn’t exists any longer when loading the document from DynamoDB. To them, everything looked fine (state sync’ed via webrtc) until the document was loaded from persistency.
How to handle this? We can’t wait for ack’s from DynamoDB as this would slow down collab editing (webrtc is great for that!) Yet, not waiting for the ack’s means that the history can get corrupted in DynamoDB.
Hence, I got the conclusion that there might just be missing updates and we somehow need to handle this situation (instead of yjs default behavior of waiting forever for missing updates).
Are there any best practices?
Isn’t that just implementation error with your provider? If the user still has the update, shouldn’t it automatically send the update and try saving it again to DB? Or has the update disappeared from the client’s history also?
Also, have you considered using just an event queue to ensure the events are persisted somewhere even if you fail to save them to DynamoDB? Seems like an ideal use-case as you depend on the event being processed before discarding them. Adds complexity though.
Resolving the conflict with custom resolution seems tedious but I assume it could be done. You just have to ensure all documents are correctly reset to the last working version and then whatever changes were applied on the of them top reapplied.
Thanks a lot for your reply, Teemu!
A bug in the provider might indeed be one of the causes. But there are can also be other causes like network issue that only lets trough webrtc traffic but not connection to the backend.
I concluded that we can make these situations less likely (e.g. by avoid bugs) but that they can’t be excluded. So, I was especially wondering what to do when it happens. For example, do we throw away all yjs updates that are based on a missing yjs updates? Or can we fake the missing yjs updates? Or are there other options?
Hey no problem Ronny . Always curious to see on what mines other people have stepped on to prevent myself doing the same. I remember reading something like updates are idempotent so you should be be fine if some are dropped from history as long as they are then synced back up with the master doc (so everybody has the same history). But somebody has to correct me on this.
But I just now realized the fact you are using serverless architecture is probably why this is a lot more problematic in your case, you are still keeping the yDocs in memory? And it’s not just append-only saving of updates?
Hopefully you’ll be able to resolve it without much further head scratching! Debugging the syncing between server and clients is definitely not easy though.
Thanks for your feedback, Teemu! Indeed, serverless on the backend means that we can’t keep the yDocs in memory - which complicates matters quite a bit. We do store only the updates - so in that sense it’s append-only.
I remember reading something like updates are idempotent so you should be be fine if some are dropped from history as long as they are then synced back up with the master doc (so everybody has the same history).
Indeed. The crux of the issue is: what do you do if you can’t sync them back because they got lost for good. Unfortunately, still no good answer to this question…
Yeah the fact you dont have the yDocs in memory means the server wont be able to use the normal Yjs route of checking whether updates are missing and syncing them back up. So I suppose you have to create your own verification step alongside just the saving of the updates.
How about if you always send the previous update’s clientID+timestamp/unique id which you always check from DynamoDB when you insert your update? Then if it’s not equal you load the doc and sync the missing updates? Hmm does sending updates out of order cause that to fail(?) Well you’ll waste a lot of bandwidth asking clients to order their updates, ending up with an OT-like solution like prosemirror-collab.
I suppose if there’s an easy way to check if an update went missing you could then load the doc and let Yjs do its thing. Having the server just insert stuff into DynamoDB could cause a deadlock if an update was inserted to DynamoDB which the client didn’t receive and is not being sent back to clients. So you must be able to push updates back to clients too.
Yjs guarantees that all clients sync up when they received all updates ever created. It is the responsibility of the provider to make sure that all updates are distributed. y-webrtc and y-websocket are both based on TCP connections. So it is not possible that a single update message just gets lost. The connection may break, but then trigger a full sync with the other client/server.
There is little you can do when the provider loses a message. So my recommendation is to find an approach that ensures that this doesn’t happen.
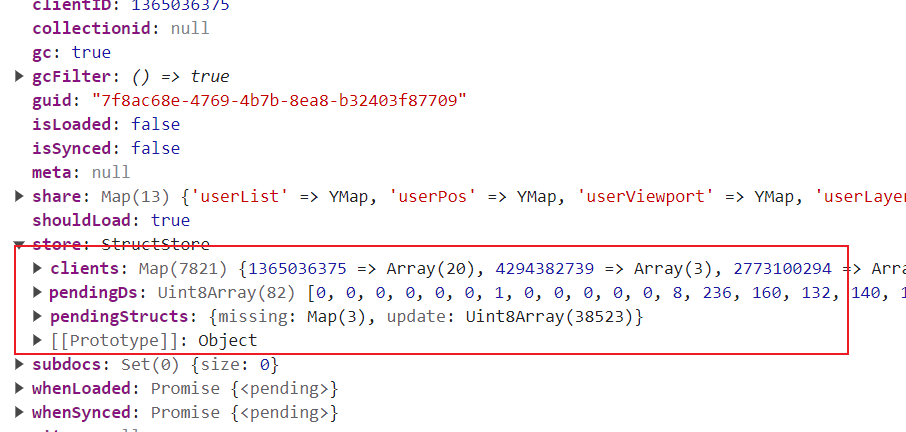
If you want to get rid of the pending updates that are distributed between all clients you can set ydoc.store.pendingDs = null; ydoc.store.pendingStructs = null. But at this point you need to accept that an important message was lost.
I’m sure you wanted to hear something different. You are looking for a solution that will repair a document when a message was lost. However, something like this doesn’t exist yet (not to my knowledge). In the space of collaborative applications, I’d argue that we don’t want to tolerate the loss of content. Imagine a user storing very important information in a document (e.g. the password to a crypto wallet). It is our responsibility to keep that data safe (e.g. by eventually converging after all messages have been received). We can’t even lose a single keystroke. This is why ydoc.store.pending* exists and why we also propagate pending messages. I recommend not to delete this information as it will also uncover bugs in your provider.
and how can i set ydoc.store.pendingStructs on the server side ,it seems that
ydoc.store.pendingStructs = null in my javascript code doesn’t make any sense
everytime i refresh the page , the value ydoc.store.pendingStructs won’t change.