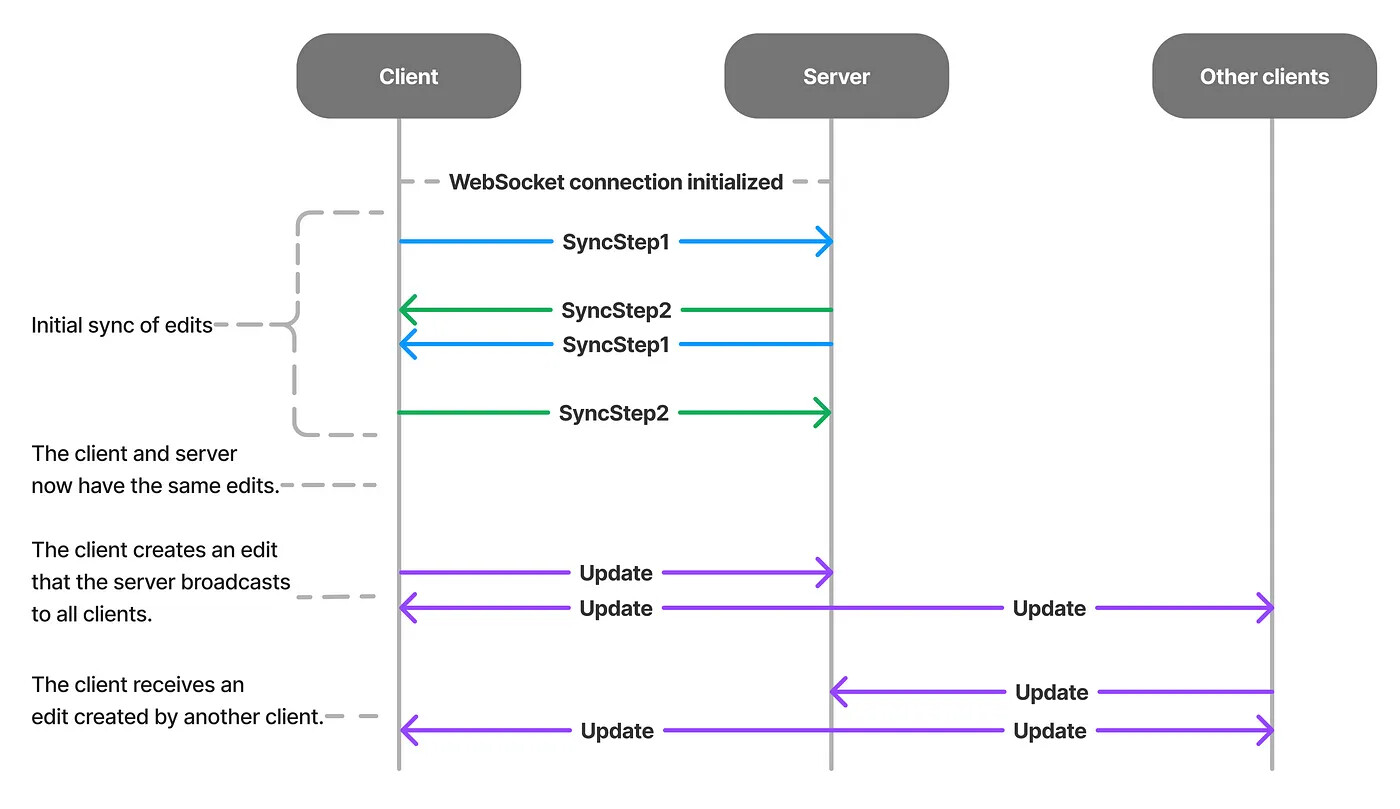
Hi,
I am currently trying to implement real time collaboration for a Map application where app state must be communicated in real time to other clients. This is a generic JSON configuration object with some settings, colors, etc.
I have decided to implement this using POST requests + Server Sent Events. I have been able to get awareness working perfectly like this, but run into issues when trying to send updates on documents which are initially loaded from a database. My approach (which im 99% sure is erroneous) has been to (at the UI client) fetch the persisted configuration from our psql database, create a new Y.Doc on each browser client, then insert the persisted configuration into the new doc via Map.set()'s. On any further updates, i encodeStateAsUpdate and send that via POST up to the server, which simply throws the message into a Redis pub/sub channel, which an SSE endpoint subscribes to which then send those messages down to the clients.
For context, my backend is a set of load balanced instances of the same api, so multiple api instances can be handling requests from multiple users
My issue is that occasionally, changes from one client are successfully propagated to other clients, but not applied. However, when I push an edit from the client where the changes weren’t applied, the changes do get applied on the original client. In that initial state where one client hasn’t pushed edits though, it sometimes gets stuck receiving updates without applying them. After reading a bunch here, my guess is that I’m either initializing the documents incorrectly, or not properly performing the sync steps described in the docs. That said, I wanted to try and implement a SSE Provider similar to the existing WebSocket provider in order to potentially solve my problems, and I had the following questions i was hoping to get answered. Lastly, if there’s anything else glaringly wrong with my approach i would love to get some feedback.
-
Is there anything i could do with this current implementation that would fix my issues so that I don’t have to implement this provider?
-
In this new provider, if the server is handling receiving and pushing messages in different request handlers, how does syncing work?
-
Does a Y.Doc instance need to exist on the server in order to sync properly with the clients? How does this impact or how is it impacted by #1?
-
Who is responsible for writing the latest updates to a database for persistence? Specifically i was wondering how the discrepancy between the latest persisted document and latest document (from ongoing edits) would impact users joining the document while it is already being edited by other users.
Thanks for any help, and i would be happy to provide any specific information that would help clarify or solve my issue here