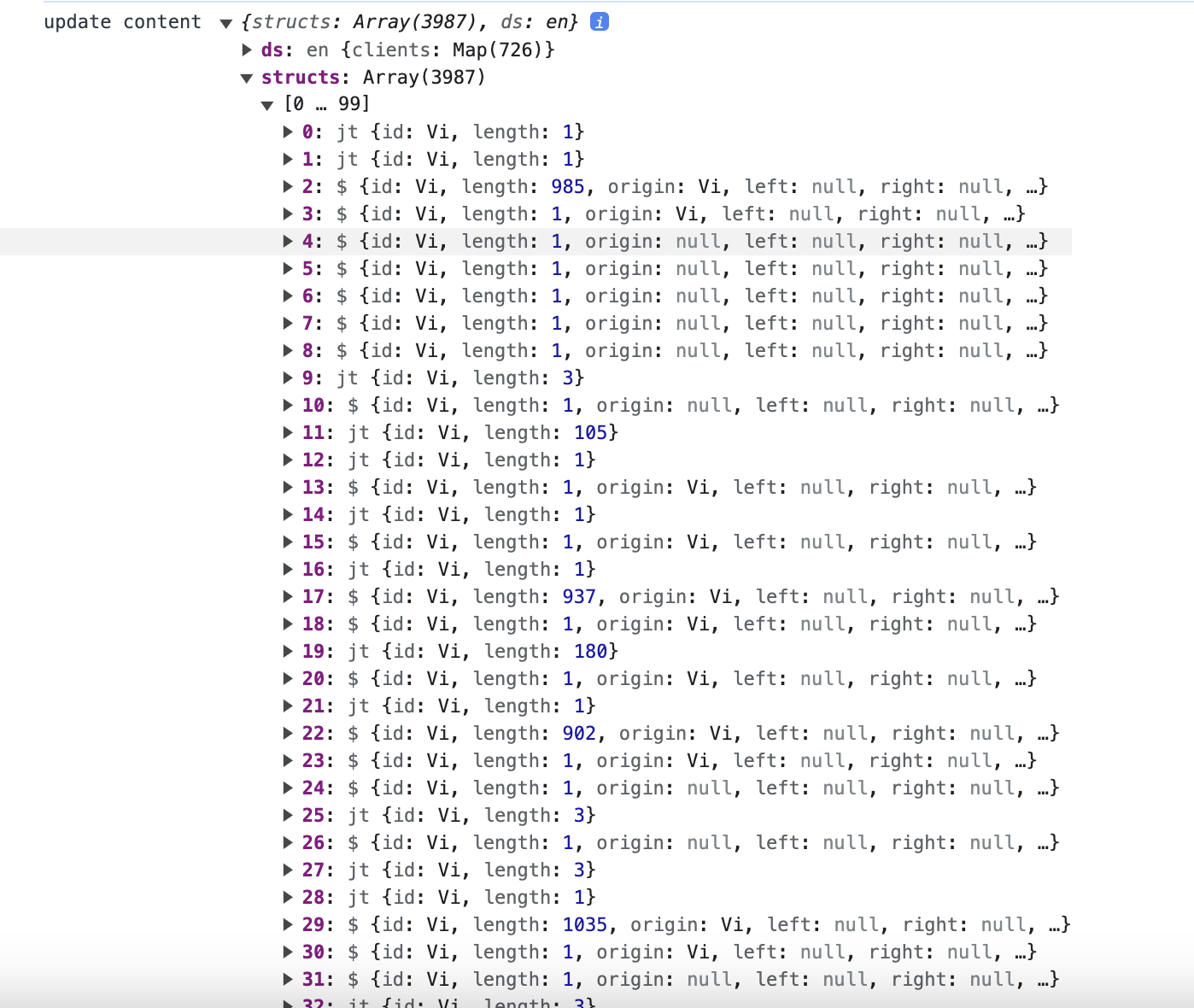
Today I found the y-websocket with codemirror6 fisrt time loading the document very slow. Then I tracing the websocket and found the download content is 2.6MB, is it possible to parse the response to know what content contains with this response? how to optimize the response with small piece data?
The easiest way to parse the content of a Doc is to add an update handler and then call Y.decodeUpdate to debug. That way the message that was sent over the wire is already decoded. The networking protocol is extremely compact so you can be assured that the size comes from the CRDT history, i.e. the updates.
I believe you can reduce the overall size of a Doc by merging all updates, but I’m not sure by how much.
YJS was built and optimized for a single Doc with a human-sized document (code, manuscript, etc). It assumes that after compression, even a large document will be downloaded very quickly over a broadband connection. For other uses cases, I think the performance claims are overstated. Many people have reported performance issues when dealing with high data volume or throughput. YJS lacks lazy loading, and doesn’t have a way to split up a Doc without losing atomicity, meaning that once a Doc exceeds a certain size, it’s very hard to avoid usability impact. There may be some alternative approaches and optimizations that can mitigate this. However it’s important to be aware of the limits and the extra work required to support data-heavy use cases.