I just learned about the new CRDT solution named Loro.
# Features
## Supported CRDT Algorithms
- **Common Data Structures**: Support for `List` for ordered collections, LWW(Last Write Win) `Map` for key-value pairs, `Tree` for hierarchical data, and `Text` for rich text manipulation, enabling various applications.
- **Text Editing with Fugue**: Loro integrates [Fugue](https://arxiv.org/abs/2305.00583), a CRDT algorithm designed to minimize interleaving anomalies in concurrent text editing.
- **Peritext-like Rich Text CRDT**: Drawing inspiration from [Peritext](https://www.inkandswitch.com/peritext/), Loro manages rich text CRDTs that excel at merging concurrent rich text style edits, maintaining the original intent of users input as much as possible. Details on this will be explored further in an upcoming blog post.
- **Moveable Tree**: For applications requiring directory-like data manipulation, Loro utilizes the algorithm from [*A Highly-Available Move Operation for Replicated Trees*](https://ieeexplore.ieee.org/document/9563274), which simplifies the process of moving hierarchical data structures.
## Advanced Features in Loro
- **Preserve Editing History**
- With Loro, you can track changes effortlessly as it records the editing history with low overhead.
- This feature is essential for audit trails, undo/redo functionality, and understanding the evolution of your data over time.
- **Time Travel Through History**
- It allows users to compare and merge manually when needed, although CRDTs typically resolve conflicts well.
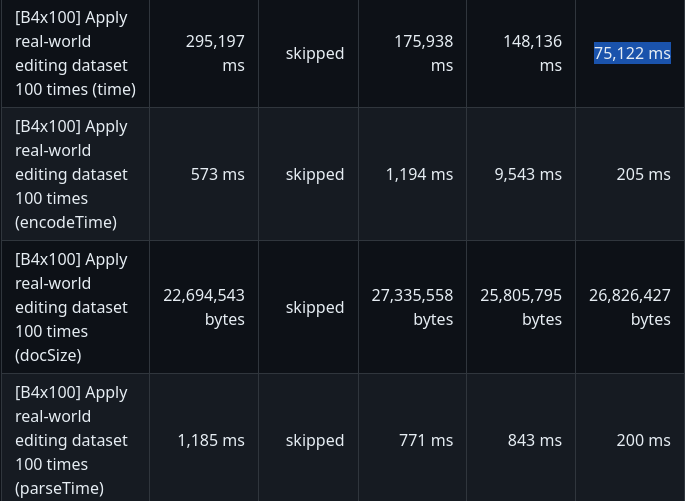
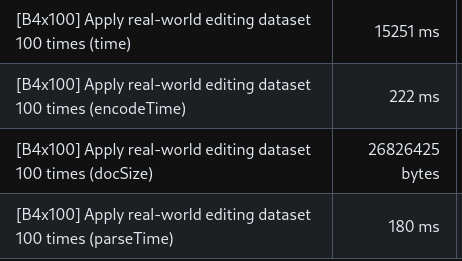
- **High Performance**
- [See benchmarks](https://www.loro.dev/docs/performance).
> **Build time travel feature easily for large documents**.
I was wondering if anyone has tried it out yet, and what the main differences (features, DX) are when compared to Yjs?